














Hello everyone! In this post, I’m talking a little about how we use MongoDB with Laravel at Convenia and what advantages it has brought us with embedded documents.
As developers, we are very familiar with the Relational model, so it is common for us to make the mistake of modeling any type of database in the same way that we model a relational one. To emphasize the difference in modeling, let’s try to imagine relational modeling for the screen shown in the following image, then let’s try to reproduce the same modeling with MongoDB:
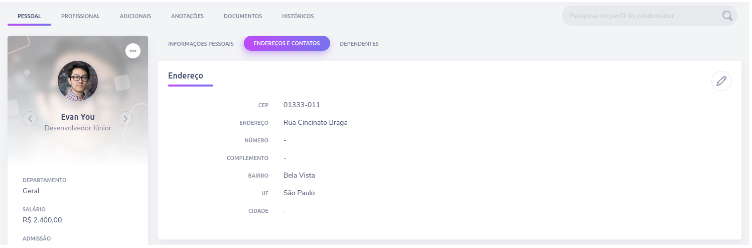
In the image above, we have two sections, the card on the left containing general information about the collaborator and the card on the right containing “Address”. In a more classic way, we would model this in two tables, always keeping in mind to avoid any duplicated information:

On the application side, we will need two models to “give life” to these two tables. The Laravel model is an active record implementation. In this pattern, we usually map one table per model. This model will play the role of our entity and is responsible for accessing the database.

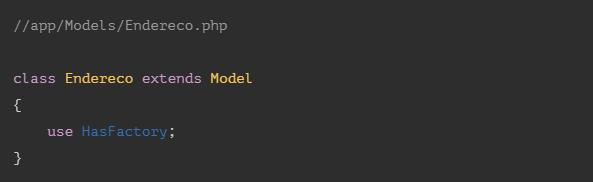
In our case, the main Model is the Collaborator model, which maintains a connection with the Address model through the addresses method, which in itself is a HasMany relationship (Collaborator has several Addresses) whenever we want to bring the collaborator together with the address we have two options:
We can do a Lazy Loading:

The code above will result in two queries: The first brings the employee, and the second, bring the address. The second is executed when calling the address relationship (represented by -> addresses). The query structure will look like this:

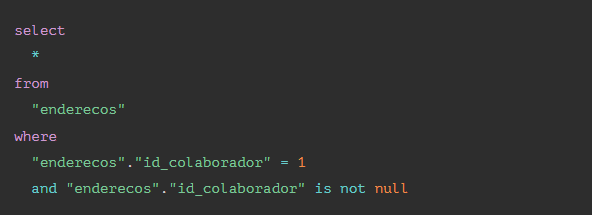
As you can see, two queries are not a big problem, but if we had a collection of collaborators, we would have the famous problem of N+1 queries, so with ten collaborators, we would have a query to bring the collaborators and then ten queries to bring the addresses of each collaborator one by one, to solve this problem we can do an Eager loading:

Now we are bringing all the collaborators with addresses. The call to the with method instructs the ORM to obtain the addresses of all the collaborators in a single query:


Note that the result of the collaborator query is used in the address query, and Eloquent itself knows how to combine the address data with the collaborator data under the hood.
With the above explanation, we can come to the conclusion that the query above is not that problematic, but let’s think that the collaborator in real life has many more relationships, to exercise, try to structure the following relationships in your mind: absences, contactInformation, dependents, documents, notice that in a real scenario the number of separate queries that we need to do can bring us a performance problem, this example is a real one, it is a small piece of our collaborator entity, it would not be an exaggeration to talk about dozens of relationships.
Now that we’ve seen an example of modeling in MySQL (relational), how would this same example look in MongoDB, and what would be the advantages?
MongoDB is a document-based database stored in JSON format, unlike MySql, it has a flexible schema, which means that you can change the document structure according to your need, without worrying about creating migrations.
The most widespread package to work with Mongo in Laravel is Laravel MongoDB, that “imitates” eloquent ensuring the same interface, and brings us many possibilities, see how the same modeling would look in a single collection in Mongo:
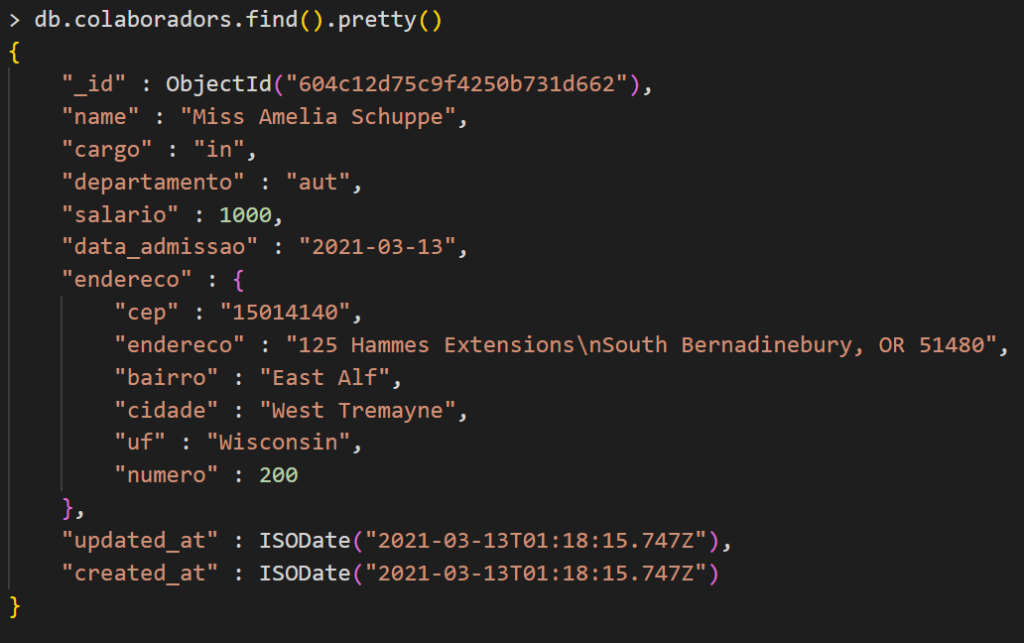
MongoDB presents a different modeling paradigm, a relational database based on the entities and their relationships, seeking a significant normalization and avoiding duplication. When modeling collections in MongoDB, we model based on the query. We can even have two different collaborators’ collections for distinct queries, of course, this brings us some challenges in writing because we will have to keep both collections updated, but we gain a lot of performance in reading is not wrong to even think about keeping the same duplicate data in the same document, however in different formats, a “raw” version of the data and another formatted version ready for display.
In the document modeled above, the collaborating entity has the address embedded. When we query the collaborator with just one query, we receive his address “for free”, imagine that in the real example of Convenia, where we have a series of collaborator relationships, just one query is enough to bring the collaborator in full, this brings nice performance gain!
The package brings us a special relationship to handling embedded documents, embeds many:

This allows you to maintain the same Entity modeling on the application side, having a specific model for the address. When storing the ORM, it will understand that it must embed (upset the record) the address inside the collaborator’s document.
You may be asking yourself, “But what if I want to share the address with more than one collaborator?”, in which case, keep in mind that the conventional relationship types (hasMany, hasOne, belongsTo) are still available, which case, the modeling remains much like MySql templating, there are cases where this is welcome:
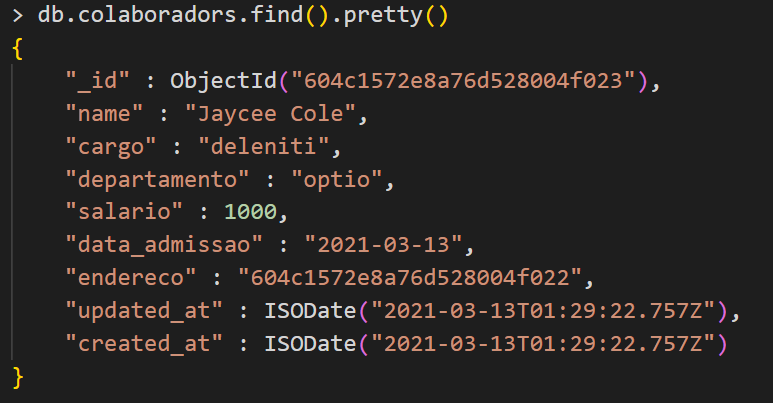
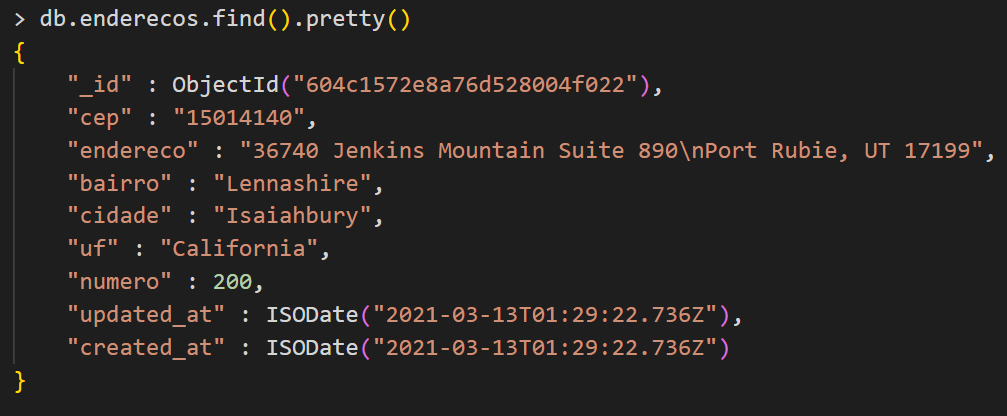
As shown above, note that it is possible to reproduce in MongoDB any structure that we would do in a relation database, keep in mind that MongoDB does not have the join operation, a similar one in MongoDB would be the lookup, using “Laravel MongoDB” we need to make a raw query, which is quite clumsy despite perfectly fulfilling its role.
Alright, but how do I decide which type of relationship I should use?
The Role of the Entity
Well, there is no perfect recipe for deciding what we should embed or not, but we have signs that we must evaluate to make that decision. All these signs will determine the entity’s role in your system. Let’s evaluate the address entity as an example.
Do we need to share that address between multiple contributors? If you don’t need to share the address, it’s a good sign that the correct thing would be to embed this data. If we need to share the address, it might be smart to define a collection of addresses as it avoids the effort of updating several collaborators when updating a single address.
Where do we need to display the address? Do we always need to show the entity to which it belongs (collaborator)? Here you can argue that we are letting the layout guide the modeling, but in fact, the layout says a lot about the importance of a certain Entity in the system. If the address is always displayed together with the collaborator, we must suspect that the address does not have the protagonism necessary to compose your collection.
Are the routes (REST) in which the address appears, are they the routes of the address itself, or are they the collaborator’s routes? If the address information is displayed only in contributor routes or in a child route of the contributor (nested resource), then we should take this as a sign that the address should be embedded in the contributor.
Are there many procedures that only take into account the address? Let’s understand the search as a procedure. It is not common to search for employees by address, only by data such as name, department, and position, this also indicates the low protagonism of the Address model.
Is there a lot of access to the contributor only to see the Address? It is possible that all the statements above lead you to understand that you should embed the address, but it is possible that people use the address a lot for some reason (sending snail mail perhaps), in which case it may be necessary to give the address its collection, that will prevent address readings from competing with employee readings, of course for this to work the address screen must be remodeled, so as not to display other data, it is also obvious that the team designer will not like this, right, but that’s to see if worth it or not.
If you compare your entities with the list above, you will see that in most cases, the entities that must be embedded are what we call “weak entities”, they are entities that have no reason to exist without a “strong entity” in which they exist, belongs.
Relational databases and JSON fields
Almost all modern relational databases bring some flexible schema solution. I would be very partial if I didn’t comment on this, MySQL for example, has JSON fields that allow us the same results mentioned above, as well as the same analysis of “role of the entity”, and this would work very well with Laravel and its custom casts feature, without a doubt you should take this possibility into account, in our case we ended up choosing MongoDB due to other advantages such as the aggregation pipeline, which is a tool very powerful to filter and transform the results, a feature that needs a single post just for it.
Conclusion
MongoDB is a complete tool and certainly has a lot to offer, however, most applications are perfectly served with the good old relational database, and if that is your case, I suggest that you choose the known one because every new technology brings a learning curve as well as its challenges, MongoDB is no different, I intend to write a post showing all the challenges we went through with it, and there were not a few ?
I hope I have contributed in some way!


Leave a comment