















Hey guys. Event-driven is a very widespread architecture in microservices because it promotes decoupling between different services. At Convenia, we opted for this architecture, and in this article, I would like to expose a little of what we did and how we did it.
First, I would like to say that we made choices taking into account our scale and growth forecast. This stack may not be ideal for you, and as it is a broad topic without a formal definition, we have taken some initiatives that make a lot of sense to us but might not fit well in your case. Despite that, the following text is likely to be constructive if you’re considering doing something asynchronous and decoupled.
How does event-driven architecture work?
Every mature framework these days comes with some event bus. If you are familiar with this concept, think about it more broadly instead of having a class that fires an event and N classes of Listeners that listen to this event, we would have an issuer service and N “listener” services. If that didn’t help you understand, I’ll explain a little better:
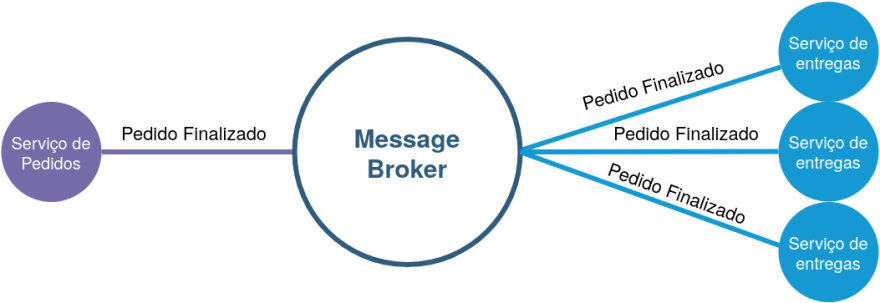
In the image above we have some important elements:
Issuing service (Order Service): it is the service from which the stimulus originates, it is only responsible for closing the order, and at the end, it shouts: “Order Finished”! That way, all the other services that care about this “stimulus” can react to it. The sender service does not know the services that “look after” for its message. Its action ends entirely after the message is issued.
Listener Services (depicted on the right of the figure): The three services care about the message issued by the ordering service, but they do not know about the ordering service itself. From that on, they can do whatever they want with the message issued without influencing the service issuer or even without influencing other listeners, very different from what would happen in a procedural approach.
Message broker (the central piece): This element is responsible for promoting the temporal decoupling between the sender and the listeners, meaning that the message is issued when the sender deems it convenient and without him caring if the listeners will be able to hear the message at that time. Listeners can listen to the message whenever they want. If a listener is offline or even “broken”, the message broker will “hold” the message until that listener can receive it.
How does this all fit into the Convenia ecosystem?
When choosing parts from the stack, we try to keep the complexity as low as possible so that the stack doesn’t burden us and that development remains simple. We opted for rabbitmq for its simplicity of use and setup and for being a robust enough option.
On the applications side, we use PHP with the Laravel framework, and this has brought us a lot of agility in the development of applications, but there are almost no solutions to make all services work as a unit. So we did a lot on our own.
Right at the beginning, we started to make the communication between the services with the most widespread php lib, the amqplib, which despite fulfilling its role and being performative enough, seems clumsy and is practically immovable (untestable), in addition to obliging us to write an inelegant boilerplate.
To solve this problem, we wrote Pigeon (I suggest reading the documentation), which wraps around amqplib, giving us the possibility to test emissions and write a truly elegant code.
Pigeon also allows us to treat rabbitmq as disposable, and instead of maintaining a versioned queue definition file, Pigeon can create queues on the fly and bind them correctly. If something goes wrong, we raise another instance of rabbit, and everything will work.
Here is an example of issuing an event with Pigeon:
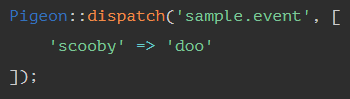
To listen to the above event, we could do the following code:
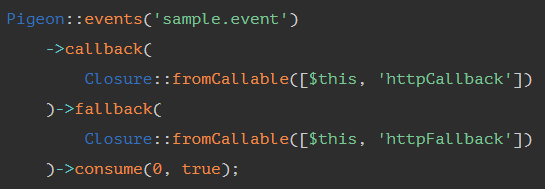
In the example above, we define a Closure for a callback (when everything goes well) and another for a fallback (when something goes wrong). Pigeon is very complete, and I intend to go into more detail in another post, but for now, I believe this demonstrates well how communication between services happens.
How to design a Listener?
The listener is the class that will contain the code that listens to the events (code presented in the previous item). This code opens a socket with rabbitmq and listens for events, meaning the listener process will never “die”. Therefore, we need to take some special care because, by default the PHP programmer is used to the request life cycle, which is very ephemeral, and this allows us to make some transgressions that, when committed in a Listener, can cause a lot of headaches. Here are some necessary precautions:
The listener needs to run on the supervisor, always: This is not only advised for programs written in PHP, but the vault also is a tool to manage secrets written in go, and it is advisable to run it on the supervisor as well because the supervisor can revive your process if it dies, without it your listener would die. Without it, your listener would die, and you would need to do a manual process to revive it, and with a dead listener, the service is “deaf”.
Correctly configure the supervisor: It is important to pay attention to the supervisor settings related to attempts. In extreme cases, the supervisor keeps trying to restart the broken process infinitely, causing high CPU consumption. In simpler setups, where the web server is in the same instance as the Listener, this would be catastrophic as the web server itself would be impacted. Think that if you use some service to manage exceptions, like a sentry, there is usually a quota that you can overflow this quota with the supervisor’s infinite attempts and lose visibility.
Separate instances of listeners from instances of web server: to avoid the situation of the previous item, it would be a good practice to have instances of “Worker”, which run only this listener. These instances tend to be simpler, as they don’t need to be accessed via HTTP. In clouds such as AWS, this would save the cost and effort of setup with a load balancer.
Avoid wasting resources: Now, the process remains alive for a long time, so we must be careful to close the connections we open and not do any type of procedure that could accumulate during the consumption of rabbitmq messages. Suppose you copy an image to resize it and forget to erase that image at the end of the process. Soon you will run out of storage. This is very common to happen with memory usage.
Artisan commands: Artisan commands are for one-off procedures, ephemeral things too, and not for “long-running tasks”, despite the conceptual transgression they are a structure option to make a listener. Inside it you will have access to all the structures of Laravel. Keep in mind that artisan commands consume a considerable amount of memory.
Idempotency: Messages can be resent. So the same message can arrive at the same listener two times. Your listener needs to process this message in an Idempotent way. Imagine that he creates a record in the database with an id “auto increment”. If the message arrives again, he cannot create another record perhaps an upsert would be the way out in this case.
Reject the message in case of failure: this we will explain in the next item.
And when things go wrong?
Of course, at some point, things will break. The broken listener tries to reprocess the message the number of times stipulated by the supervisor configuration, and then it will die. And when things go wrong? In this case, the message will be dammed in the queue until the listener is corrected. After the correction is deployed, the message is correctly consumed, and everything goes back to normal.
The above situation is not ideal, as the listener often dies only for a given message. Rabbitmq has a dead letter exchange configuration that allows us to send the message to a specific location in case of failure, at our case, we reject all messages that caused a failure.
Now we receive all the broken messages in a single place, but we should give more visibility possibilities for these messages, so we created LetterThief (Letter Thief), a service that aims to notify all the failures and gives us the possibility to resend the messages that caused this failure.
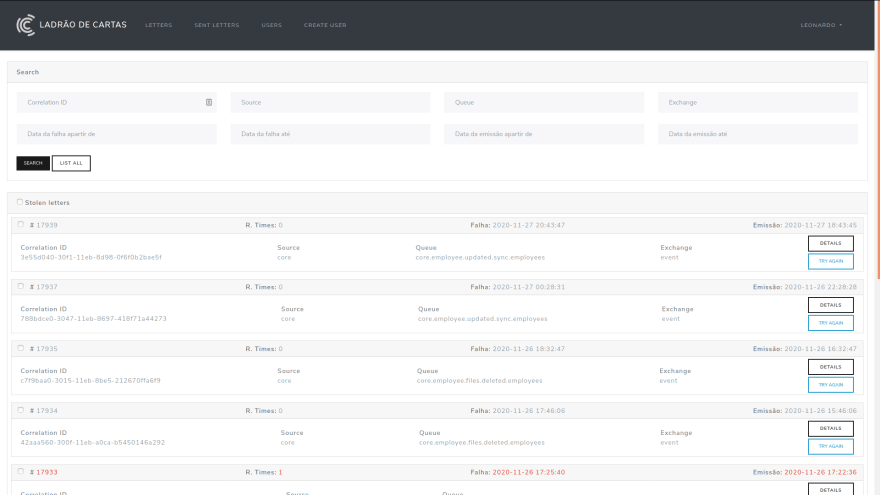
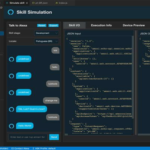
The image above shows the Thief interface, with some actions with emphasis on the “Try again” action. This button gives us the possibility to resend the message to the service from which it originated.
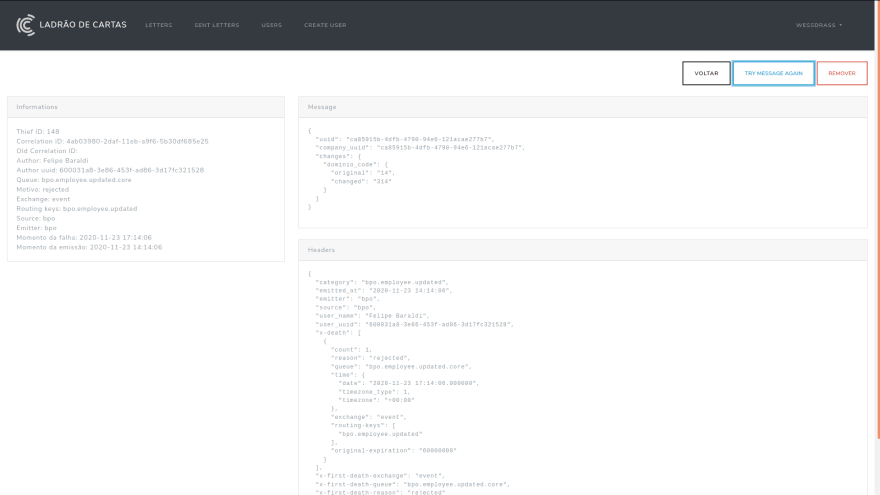
When opening a message, we have various information such as metadata, headers, and body. These will allow us to reproduce and correct the error in a local environment. Only after deploying the fix should we resend the message.
Just damming errors in a specific place is no use. We have to sound an alarm warning about this error. In our case, we have a slack channel where all the errors fall, the following figure shows how this works:

When we see the notification in Slack, we know which developer is responsible for fixing the failure precisely by the queue name. This developer will immediately focus on that fix.
Conclusion
Every distributed architecture will be relatively more complex than a service in a single repository, but I believe we managed to arrive at a relatively simple and secure architecture compared to the standard used in microservices on the market. Each case has a specific need, so it will hardly work completely for you, but you might get some idea of it all, and mainly, never distribute your architecture if it’s not really necessary.
I hope I have contributed in some way.




{kind=link}
Leave a comment